
Customer Churn Prediction App
May 25, 2025
Project Overview #
This project tackles the challenge of predicting customer churn using machine learning. I built and compared three models — Logistic Regression, Random Forest, and a tuned Random Forest — to identify which customers are most likely to leave a service.
The models were trained on telecom customer data, and I deployed all three in an interactive Streamlit app. Users can explore each model’s performance and test different service scenarios to see how likely a customer is to churn.
Business Value #
Customer churn is a major cost driver in subscription-based services. By predicting churn in advance, companies can offer proactive support, targeted incentives, or long-term contracts to reduce attrition.
This app helps businesses:
- Identify high-risk customers based on usage and contract patterns
- Visualize key drivers of churn
- Make data-backed retention decisions
Key Results #
| Metric | Logistic Regression | Random Forest (Tuned) |
|---|---|---|
| Accuracy | 73% | 75% |
| Recall (Churn) | 79% | 71% |
| Precision (Churn) | 50% | 52% |
| ROC-AUC | 0.83 | 0.83 |
The Logistic model caught more churners (high recall), while the Random Forest was better at avoiding false positives (higher precision). Both models had solid ROC-AUC scores, and tuning helped balance Random Forest performance.
Insights from the Data #
- Customers with high charges and short tenure are most likely to churn.
- Those on two-year contracts are far more likely to stay.
- Fiber optic service shows a stronger link to churn — possibly due to pricing or performance concerns.
Tools Used #
- Python (Pandas, NumPy)
- Scikit-learn (modeling + evaluation)
- Streamlit (app deployment)
- Matplotlib & Seaborn (visualizations)
- GridSearchCV (model tuning)
Try It Yourself #
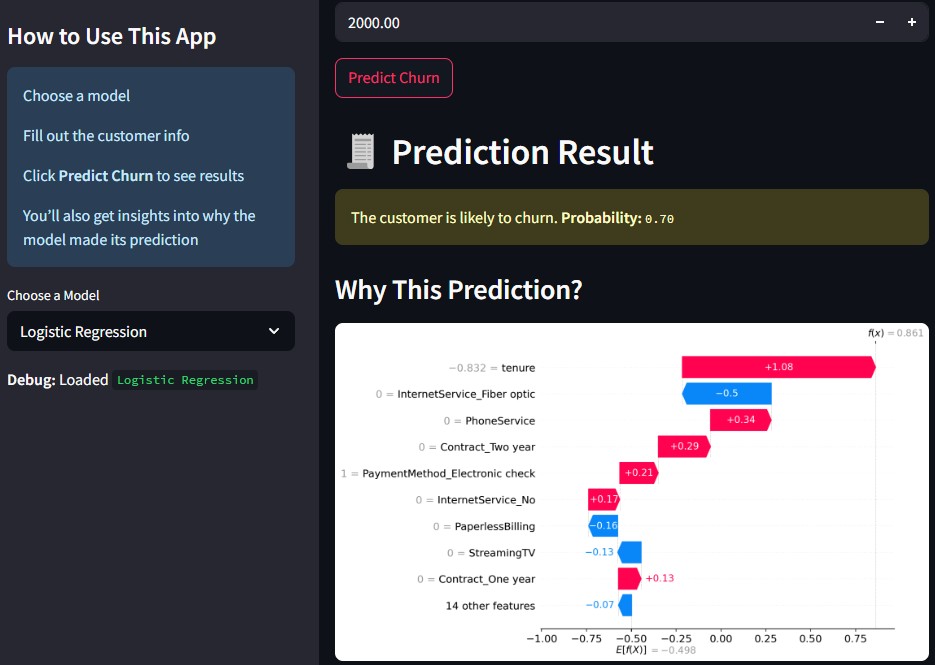
App Interface Preview #
Here’s what the deployed app looks like in action — with real-time predictions and model explainability:
What I Learned #
This project strengthened my skills in:
- Working with imbalanced datasets using class weights
- Comparing models not just on accuracy but precision and recall
- Deploying ML projects with Streamlit for real-time interaction
Last updated on May 25, 2025